







AI can optimize processes, increase efficiency, and open up new business opportunities, radically changing the way you compete in your industry.

Cookies
We use our own cookies and third-party cookies to obtain statistical data about our users' browsing behavior and to improve our services. If you agree and continue browsing, we assume that you accept the use of cookies and our basic terms.
Cookies Policy.Articles
Rethinking Text Processing: Why H-Net May Replace Tokenization
In recent years, artificial intelligence has made great strides thanks to the abandonment of specialized models for specific tasks in favor of general models based on powerful architectures such as the Transformer. A clear example is large language models (such as GPT or LLaMA), which have demonstrated the power of this approach. However, even these models still depend on a crucial preliminary step: text tokenization, that is, dividing characters into larger units (tokens) before processing.
Tokenization is an algorithm that splits text into fragments (tokens) of words or subwords following statistical patterns. The most common method is called Byte Pair Encoding (BPE), which analyzes large text corpora to determine which character combinations appear frequently and should be joined. This technique has been fundamental to the success of models like the GPT family, but it presents significant limitations. Since it is based on frequency and fixed rules, BPE often breaks words unnaturally and creates strange tokens that are barely used. For example, in English it could divide "streamlined" into fragments that cut meaningful suffixes, or generate "junk" tokens made up of word parts that almost never appear alone. This is essentially the issue behind asking an LLM, like ChatGPT, things such as "what color is Santiago's white horse?" or "how many 'e's are there in the name 'Miguel de Cervantes Saavedra'?"
Conventional tokenization, which is mainly optimized for English, also introduces bias in almost all other languages. For example, Chinese (which lacks spaces between words) is often segmented arbitrarily, separating characters that should stay together, and agglutinative languages—in which a word is formed with many morphemes—suffer unnatural cuts. But perhaps the most limiting factor is that tokenization is static and inflexible: it always segments a sequence the same way regardless of context, preventing the model from adjusting its "reading" according to the sentence's meaning.
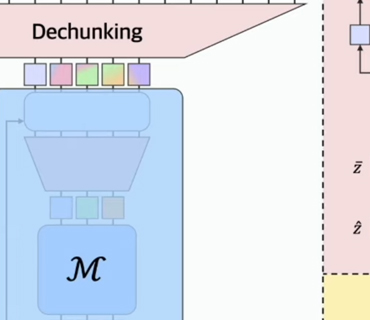
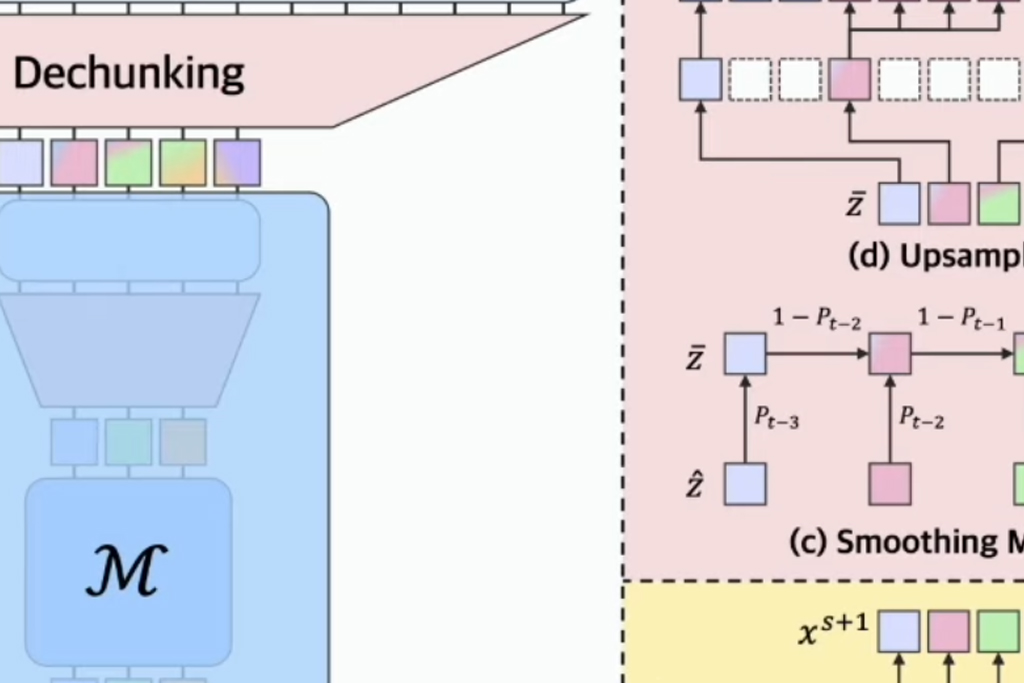
The search for alternatives led Sukjun Hwang, Brandon Wang, and Albert Gu to propose in July 2025 a different approach called “Dynamic Chunking.” The central idea of this approach is to eliminate tokenization completely and make the model itself learn to segment text on the fly, as in Reinforcement Learning, depending on content and context. In their paper “Dynamic Chunking for End-to-End Hierarchical Sequence Modeling,” the authors present a language model called H-Net (for Hierarchical Network) that processes sequences directly at the byte (character) level, integrating segmentation into the model itself instead of treating it as a separate preprocessing step. In essence, this means that instead of applying fixed rules before training, the model discovers for itself where "words" or meaningful units begin and end, depending on what helps it best predict text.
H-Net implements this vision through a hierarchical architecture inspired by the U-Net model, with several stages of compression and decompression of the sequence. In simple terms, the system works in layers. First, encoder networks process the input byte sequence and produce an internal representation of the text. Then, a dynamic chunking layer groups those representations into larger segments by identifying where there are natural contextual boundaries. Afterward, the main network processes the already "compressed" segments (which are much shorter than the original sequence, saving computation), and finally, decoder networks expand the information again to reconstruct the complete output. Unlike a fixed approach (e.g., “take every N characters”), H-Net decides where a chunk ends by analyzing the similarity between adjacent parts of the text: if it detects an abrupt semantic or topical change, it marks a cut there. This entire process is trained along with the language model so that the segmentation strategies are optimized to improve text prediction “without the need for human-designed rules.”
The consequence of this design is that H-Net achieves very promising results. In their experiments, a single-hierarchy H-Net (one level) operating at the byte level outperformed a traditional Transformer of similar size trained with BPE tokens. When two hierarchical levels were introduced, the model achieved even higher performance, matching another token-based model with twice the number of parameters. This indicates that the hierarchical architecture allows better scaling as more information is added: as training progresses, H-Net leverages the learned structure and its performance improves faster than that of the equivalent standard model. In fact, the authors observed that although the byte-level models lagged behind initially, after a certain amount of data, H-Net clearly outperformed the tokenized version.
Furthermore, H-Net proved more robust at the character level. It maintains its performance even if the input text contains spelling mistakes or unusual formats—situations where a common model might fail when encountering tokens not found in its vocabulary. Its advantages are even more pronounced in domains where traditional tokenization heuristics usually fail. In tests with Chinese text, programming code, and even DNA genetic sequences, the hierarchical model learned more appropriate segmentations and achieved up to four times greater data efficiency than token-based methods. In other words, a truly tokenizer-free model can better exploit information in certain types of complex or non-linguistic data that conventional approaches tend to overlook.
It is important to point out that H-Net is not simply “a bigger model” but a different approach. Giant models like GPT-4 or LLaMA-2 have achieved impressive results using traditional Transformers with tens of billions of parameters, but all of them require a fixed tokenization defined in advance. This means that even though they have enormous language knowledge, they share the limitations mentioned above: they cannot reinterpret how to split a new word or symbol on the fly, but depend on the vocabulary established during training. For example, if a GPT model has never seen a certain emoji or recent slang, it will break it down character by character without fully "understanding" it. H-Net, by contrast, has no fixed vocabulary: it can learn to segment that new symbol based on the context in which it appears, just as a person would when encountering an unknown word in a sentence. In other words, the advantage of H-Net does not come from training the same recipe with more data but from “changing the recipe” to give the model more freedom to learn by itself what language structure is relevant in each case. This philosophy connects with the “bitter lesson” described by Rich Sutton: instead of manually incorporating our linguistic rules into the system, we let the algorithm—armed with enough computation and data—discover the best strategy on its own.
What practical applications could a model like H-Net have?
In the short term, this breakthrough suggests important improvements in multilingual models. A single system with dynamic segmentation could handle very different languages (English, Chinese, Arabic, etc.) without needing a specific tokenizer for each language. It could also better adapt to internet slang, new jargon (especially among younger generations), or special formats like hashtags and emojis, understanding their meaning from context instead of failing when faced with unknown character combinations.
Another promising area is programming code: H-Net has shown superior results in modeling source code, opening the door to programming assistants more capable of understanding different syntaxes or even new languages without needing to retrain a model for each case. In bioinformatics, its ability to learn directly from DNA sequences—basically long strings of letters—without manually defining a “dictionary” of genes or amino acids could help discover genetic patterns more efficiently. In general, any domain where the data consists of long symbol sequences—from music to sensor readings—could benefit from the model learning on its own what the most meaningful units are.
Far from being a theoretical experiment, H-Net represents a step toward truly end-to-end artificial intelligence systems, where every level of understanding is learned directly from data. If the last decade was dominated by Transformers supported by human-designed tokenizers, in the coming weeks or months we might begin to see the rise of models that no longer need that handcrafted help, assimilating language more similarly to how humans do.
Sources:
- Sukjun Hwang et al., “Dynamic Chunking for End-to-End Hierarchical Sequence Modeling,” arXiv preprint (July 2025);
- Rich Sutton, “The Bitter Lesson,” essay (March 2019).
Latest Articles


Contact us now for an individual consultation!
Contact
Lecture Consultation
Start your
Start your
AI transformation now
-
How can AI transform your business?
-
Why should you seek a consultation?AI is more than just hype. For a company, there are many different and important aspects to consider. Let us find the perfect lecture for you together.
-
What risks does the introduction of AI bring?As your consultants, DEEP ATHENA helps you navigate challenges such as data management and security to minimize risks and ensure successful implementation.
-
How can you ensure that AI aligns with your business goals?Our consulting approach includes a detailed analysis of your business goals to develop an AI strategy that aligns perfectly with your objectives.
-
Why should you choose DEEP ATHENA?Our unique experience and personalized approach provide you with the tools and knowledge to successfully integrate AI into your business, ensuring tangible and sustainable results.
The Author
Juan García
Juan García is an Artificial Intelligence Expert, Author, and Educator with over 25 years of professional experience in Industrual Businesses. He advises companies across Europe on AI Strategy and Project Implementation and is the Founder of DEEP ATHENA and SMART &PRO AI. Certified by IBM as an Advanced Machine Learning Specialist, AI Manager and Professional Trainer, Juan has written several acclaimed Books on AI, Machine Learning, Big Data, and Data Strategy. His Work focuses on making complex AI Topics accessible and practical for Professionals, Leaders, and Students alike.
More